Narrow Gateway Hurdles: PebbleDB vs LevelDB

This article details our experimentation with PebbleDB as an alternative for LevelDB specifically for RPC API nodes, and the significant reduction in I/O bandwidth usage (~90%) we have experienced in production.
Background
Fantom’s network is a decentralised network of nodes using a peer-to-peer protocol to keep the blockchain’s ledger consistent and execute transactions safely. The ledger stores information about users’ accounts and other information such as smart contracts and their storage.
Keeping the ledger consistent and secure is, of course, only one of many tasks of Fantom’s network. Users need applications that perform transactions swiftly on the ledger. Have you ever used a Wallet, a Marketplace, or a Swap? These are the applications we all use to interact with the ledger daily.
These applications usually can’t modify the ledger directly. Instead, blockchain applications rely on Fantom's network nodes to provide standardised gateways. The applications talk to these gateways to collect relevant information about accounts and submit signed transactions on the user’s behalf.
Opera, a specialised network client, carries out all the tasks to bridge the applications with Fantom’s network. The gateway is implemented as a Remote Procedure Call interface so that applications can access the ledger indirectly. Each network node can function as a gateway, but usually, dedicated nodes are used for this role, known as RPC API nodes.

What does an RPC API node do?
An RPC node must synchronise the ledger with the network and must be aware of the latest changes to the ledger so that the applications have reliable and up-to-date information about the ledger. Besides keeping the ledger synchronised, the RPC API nodes process the applications’ queries. And there are many of them. The current average amount of RPC API requests is around 850 million daily queries combined (rpc.ftm.tools, rpcapi.fantom.network).
Side note: If you submit a transaction into Fantom’s network, it’s not added to the ledger immediately. An RPC API node adds the transaction into a waiting queue (aka Transaction Pool). Specialised nodes called Validators are responsible for placing transactions from the queue onto the ledger.
You can imagine it’s more like a hurdle race for an RPC API node to stay synchronised with Fantom’s network and handle multiple parallel requests of the applications. Note that the Fantom Foundation provides several RPC API nodes to the community for free. With the increase of the number of applications, the workload of the RPC nodes grew, and the performance of the nodes suffered.
Why should it matter to you? If an RPC API node is overwhelmed with queries, it won’t process them, and some of them will be dropped. As a consequence, applications may stall for end users. For example, you may not see your current account balance, your transaction may not be submitted to the network, and your time-sensitive contract call may just fail for no obvious reason. That’s clearly an issue that needs to be addressed.
Measurements
We have already discussed profiling on this blog. Profiling assesses performance bottlenecks in Opera’s internal software components, with a particular focus on transaction execution and the persistent state storage. However, our measurement has a different goal in mind this time.
We want to know what part of Opera exerts the biggest pressure on the host operating system and the server it runs on. If we identify the source, we may find a way to optimise Opera for RPC API nodes.
A public application gateway to query the blockchain is already available. It can be used to provide real life application RPC API requests for the measurements. The testing set was built from identical bare metal servers equipped with AMD Ryzen™ 9 5950X, 16 core (Zen3) processor with SMT, 128 GB RAM, and 2x 3.84TB NVMe drive in ZFS RAID 0 for the Opera data storage.

The number of requests sent to the servers was set to 50 per second. We tried several other request flow volumes and the chosen value does not stress the nodes yet, but already shows impact on the resources consumed.
The processor didn’t show oversubscription, i.e. the setup can handle a much higher load.
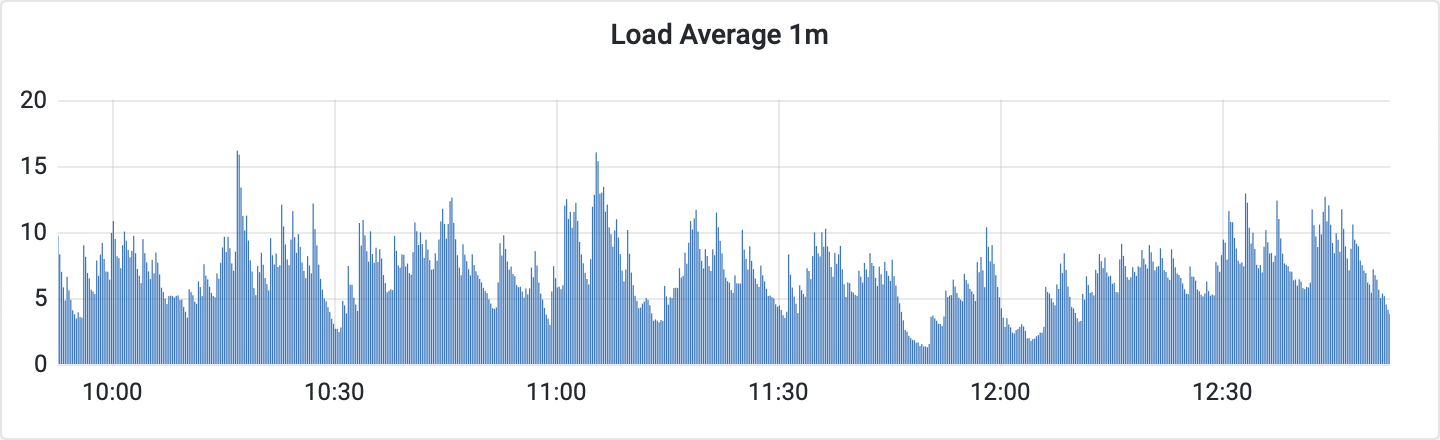
The same can be said about the number of processes. For some of its internal operations, Opera requires new processes to be started from time to time, but they terminate when the tasks are completed. It may be observed via the changing number of running processes.
The memory usage of the Opera client revealed interesting artefacts. The following diagram depicts the used memory, and the memory consumption is rather high.

We carefully investigated the processes that allocate the memory, and Opera was one of them. When the client started, memory consumption rapidly increased. It grew even faster by enabling the RPC API for opera. We investigated the amount of swap memory of the operating system to find out if this could be a problem.
The data transfer from and to the disk is very slow, and the operating system only swaps memory to disk if memory is really depleted. This wasn’t the case, as you can see in the following figure:
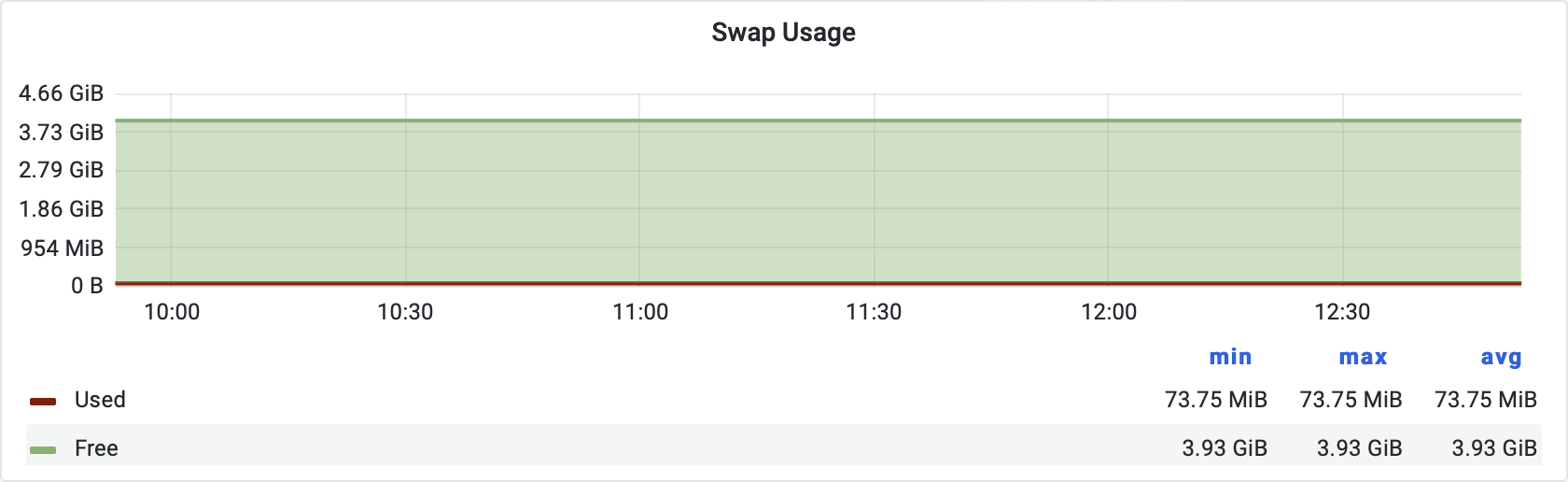
Side note: The swap is used as a last resort. If an application asks the operating system for more memory, but the available physical memory space is almost depleted, the operating system starts to move some other parts to a disk. The dedicated space on the disk is called the swap.
The next investigation was related to the disk drive I/O (input/output). Following diagram shows the disk drive I/O volume.
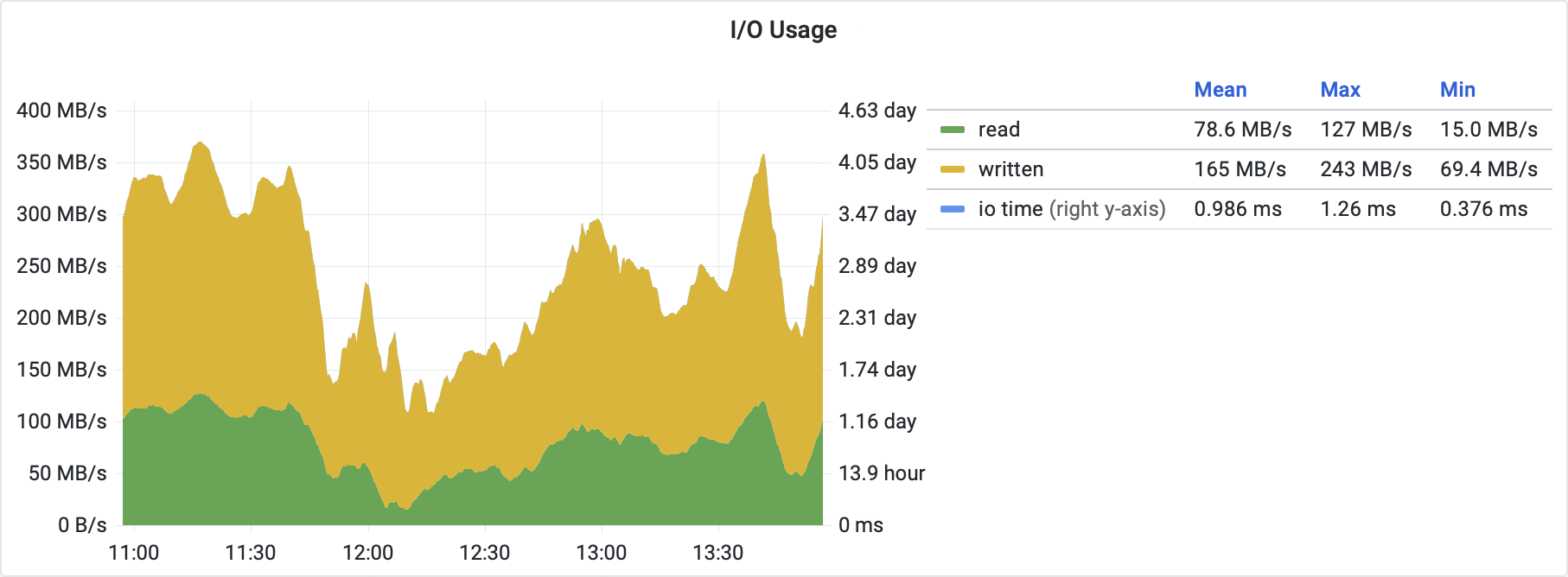
We didn’t expect the amount of drive I/O to be this high. It saturates the host system at the peaks and even the mean amount reaches up to half of the available continuous I/O bandwidth.
The Opera client uses a LevelDB key-value database to handle all its data storage. To provide fast access, LevelDB requires the data to be organised into layers and each layer must be sorted. The layering and sorting process called compaction has to be done over and over again as new data is added into the database with each new ledger record. And that’s where the I/O comes from.
The available I/O bandwidth depends on the hardware architecture of the host system. All operations accessing persistent data share this bandwidth with each other. If the LevelDB compaction consumes a significant part of it, the other operations must wait for the opportunity to pull data they need. This limits the effective throughput of the RPC API interface substantially.
We have found a promising target for optimization. If we find an alternative database, which would not require compaction, or at least not so often, we may lower the I/O and get more room for the real data pulling.
Alternative Database
We discovered that the database compaction is responsible for high disk drive I/O. The Opera client can not process more RPC API transactions if it can’t pull the data from the database fast enough.
First, we need to define the properties our alternative database should have.
- It has to be a key-value store. That’s what we use now, and going for a totally different architecture would mean a lot of changes across the critical parts of the Opera client code.
- It must be compatible with LevelDB functionality. We want to keep using the features we already do. For example bloom filters, sequential listing through the data, indexes, etc.
- It must have a Go language interface. The Go language is used for the Opera client development, and interfacing non-Go code may bring some unexpected issues in later development and maintenance.
- It must be able to be embedded into the Opera client. We don’t want to complicate node deployment with a separate database installation and maintenance.
- It must be actively developed. We want to be sure that possible issues and code errors will be addressed.
We found two candidates:
Badger is an embeddable, persistent, fast key-value database written in pure Go. It is the underlying database for Dgraph, a fast, distributed graph database.
Pebble is a LevelDB/RocksDB-inspired key-value database focused on performance, and internally used by CockroachDB. Pebble inherits the RocksDB file formats and a few extensions such as range deletion tombstones, table-level bloom filters, and updates to the MANIFEST format.
To test these candidates, we reused our testing bench and installed a modified version of Opera with the tested database. We also ran a standard LevelDB node as a reference.
Servers have been set to synchronise with the Fantom’s network from genesis. We want to know how much time it takes for each version to reach the fully synchronised state. The test was run several times and the average was calculated to mitigate the noise. The next diagram shows time to finish synchronisation in hours for each implementation.
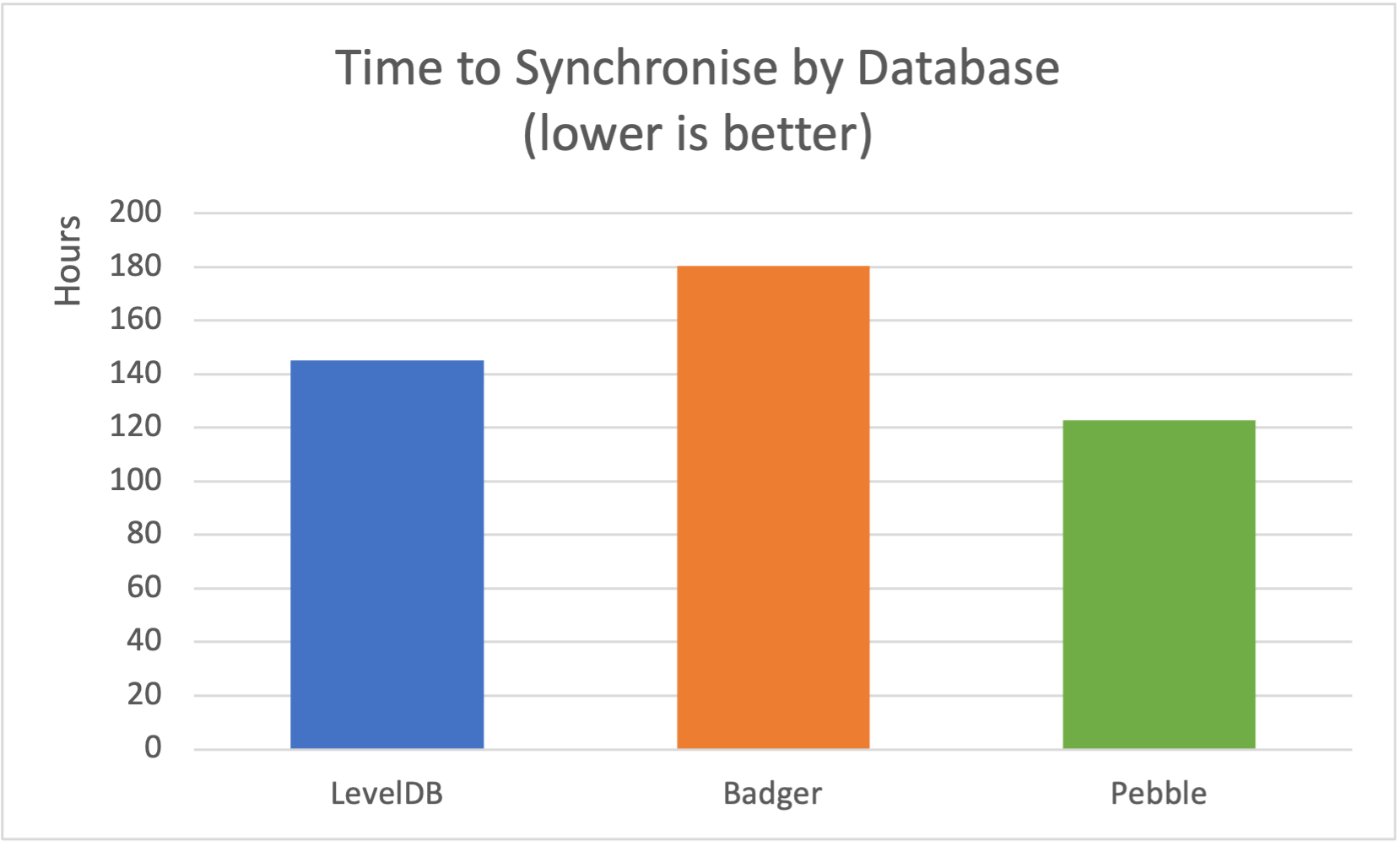
The differences are not staggering. LevelDB fell well in between Pebble and Badger, beating Badger by 38 hours. Pebble was able to sync in 122.6 hours, which is almost a day sooner than LevelDB and reduced the synchronisation time by 16%.
The second test measured the number of blocks each node is able to sync in a fixed time. This case covers a very common scenario when a node is shut down for a short time, for example to do a host operating system maintenance. Opera should be able to sync with Fantom’s network as fast as possible. The next diagram shows the number of blocks synchronised in a 60 minute window on nodes with the stable processing flow.
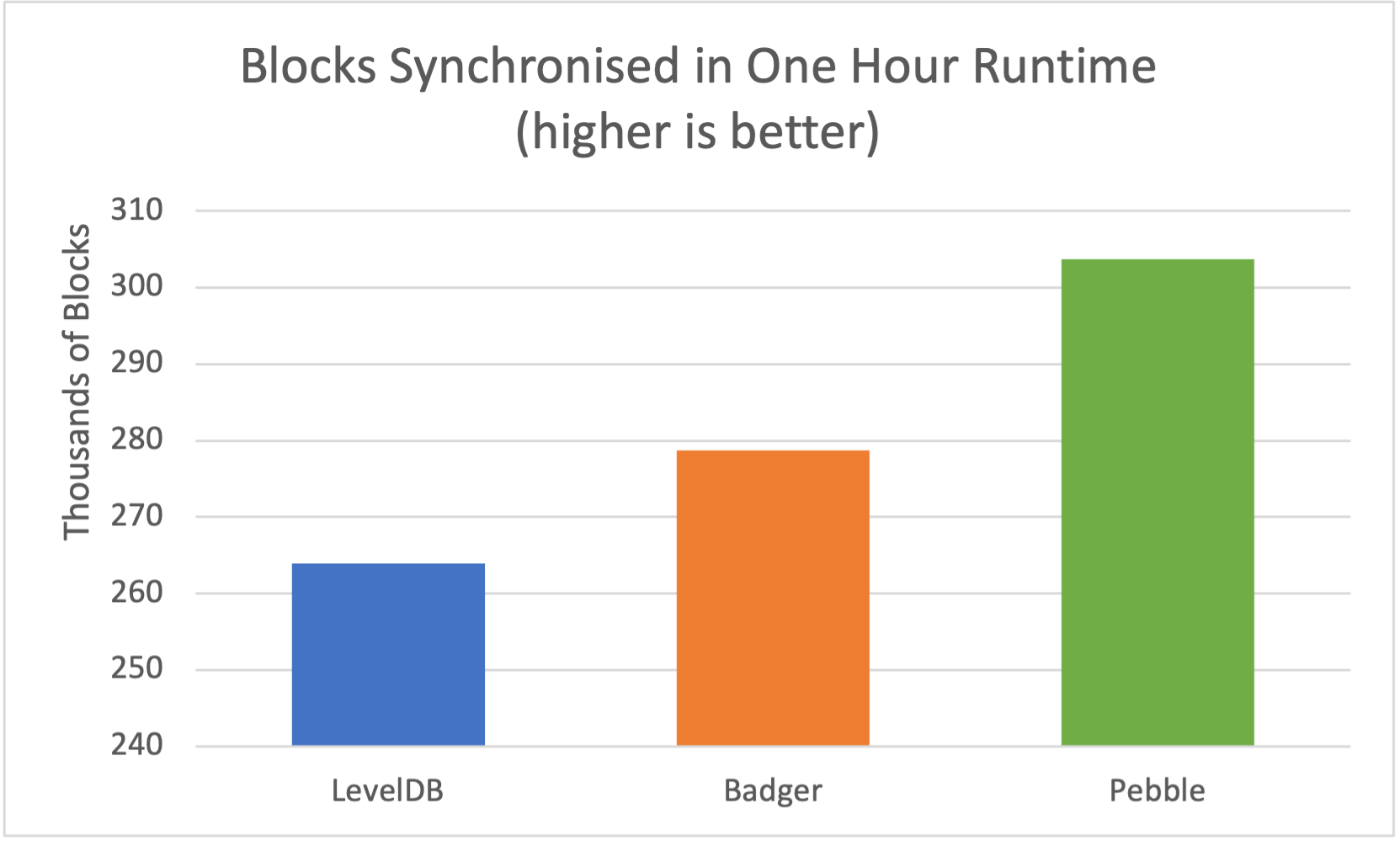
Badger was able to synchronise more blocks in a short burst than LevelDB, but the average total time to reach full network synchronisation was consistently higher by 28%. Pebble showed even better results on short-time synchronisation. It was also consistently faster in reaching full synchronisation with the network than LevelDB by 16%.
Based on these results, PebbleDB was a very promising candidate. Now, we wanted to run Pebble and LevelDB side by side and compare their performance in the RPC API handling.
Both nodes were synchronised with the Fantom’s network and attached to the public RPC API gateway. The number of parallel connections to each server is limited to 30, with each connection running only one RPC API request at a time. The following diagram shows the number of processed requests per second.
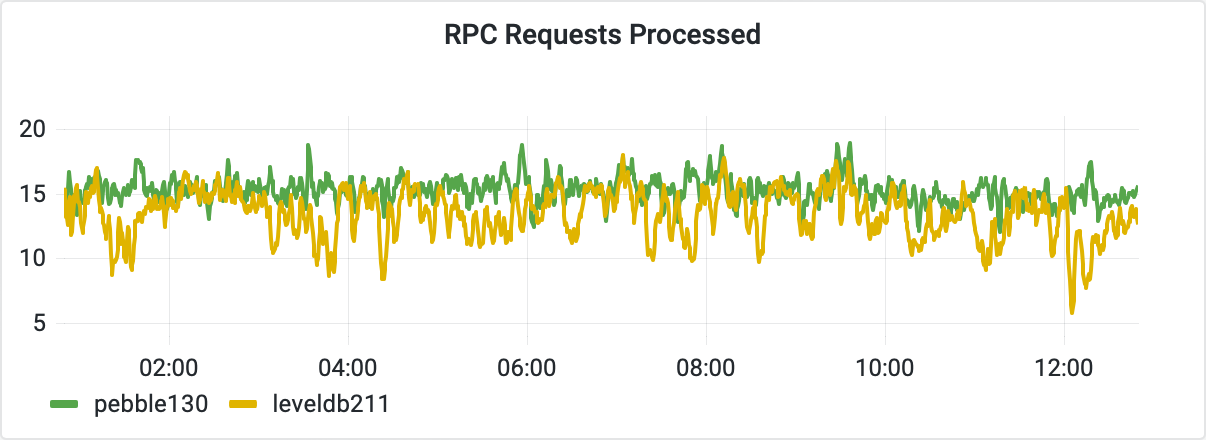
The average time Opera spends processing the most expensive incoming requests is another indicator of the RPC API performance.
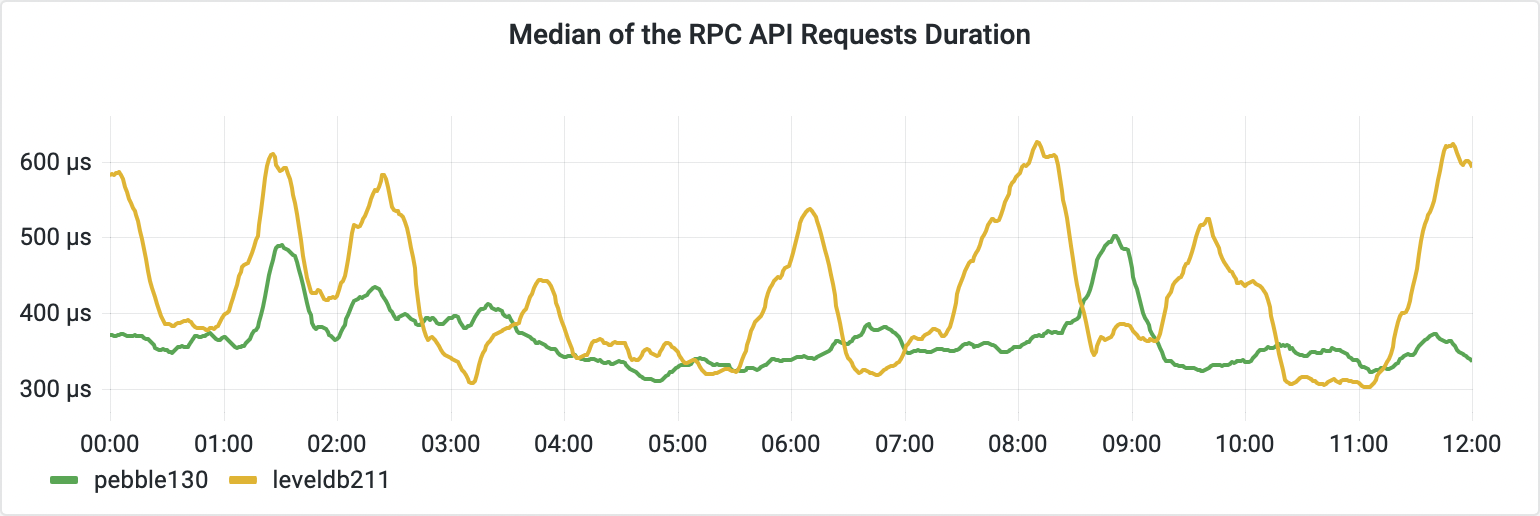
The diagram above shows the average duration of the longest requests per X minutes interval on each node. The Pebble node spent less time with these resource heavy requests on average, and so it was able to process more requests over time.
The following diagram shows the disk drive I/O consumed by each node. The high volume of I/O on LevelDB was the reason we wanted to look for an alternative database, so Pebble should perform better.
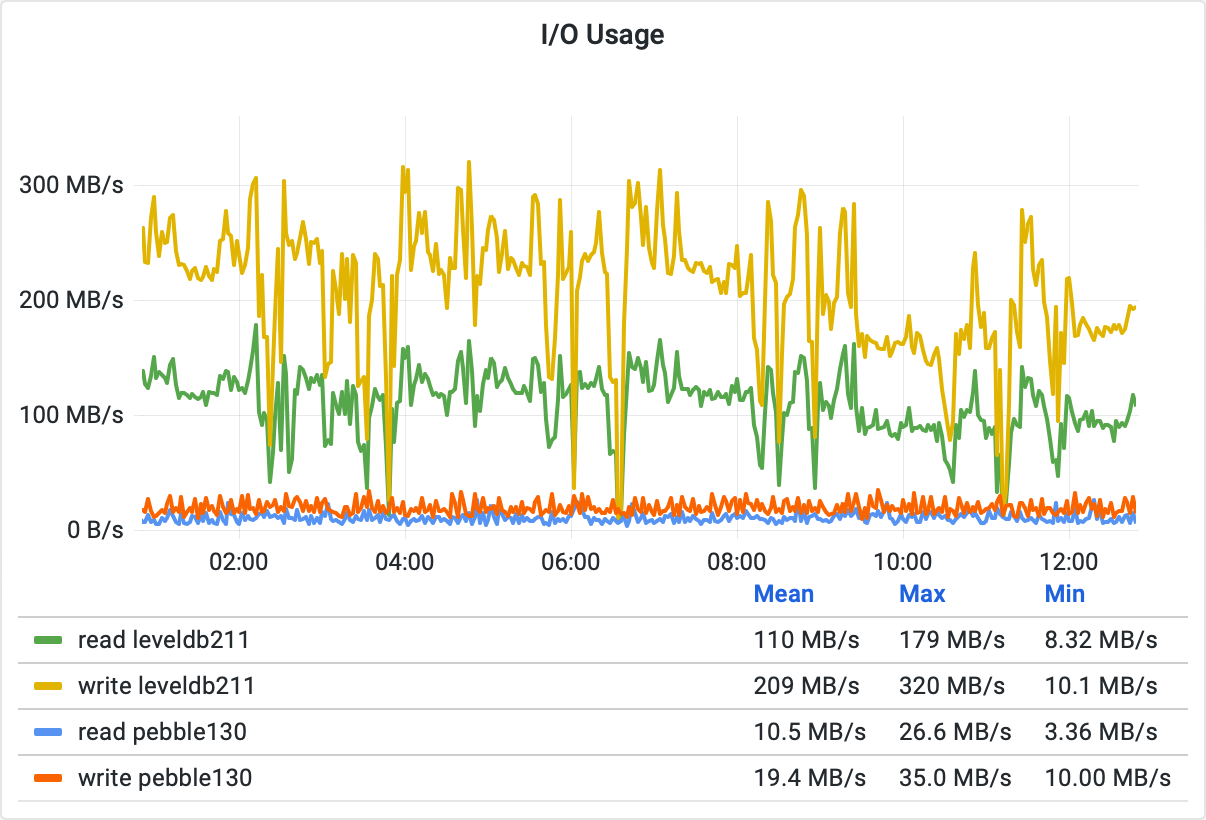
The Pebble implementation clearly beats LevelDB on this court as well. The mean amount of disk drive I/O on the Pebble node is lower by 90%.
Conclusion
We measured RPC API Opera nodes to find out why they could not process more RPC API requests. Next, we tested alternative database backends to find a better solution, and Pebble shows significant performance gain over the currently used LevelDB. Finally, we showed that the number of API requests handled by the node is higher with the Pebble and that it puts less stress on the server’s disk drives by doing much less I/O operations on average.
Also, LevelDB is used not only by the Opera client but also by Ethereum. It has definitely certified its reliability. Although we can not say the same about Pebble yet. However, there are use cases where the Opera client will benefit from Pebble. The RPC API is clearly one of them.