Client Performance - Does it Matter?

Overview
Opera (Fantom’s blockchain client) manages an ever-growing number of transactions, events and blocks. We have conducted a set of experiments to determine how the performance has changed over the first 42M blocks, whether Opera can sustain the growth, and where there is potential for improvement. In our experiments, we found that the performance has been stable, though we can further enhance the Storage access (aka. StateDB) and the Ethereum Virtual Machine (EVM).
Background
Fantom’s network is a decentralized peer-to-peer network consisting of nodes continuously communicating with each other and keeping a consistent version of a ledger (aka blockchain).
Nodes can have different roles: RPC API nodes can issue new transactions and place them in a transaction pool.
Validator nodes are responsible for securing the ledger and making it immutable. Their task is to place transactions from the transaction pool into an event data structure (shown as DAG) to reach consensus via a complex aBFT protocol.
A read-only node can retrieve information from the blockchain for further consumption.
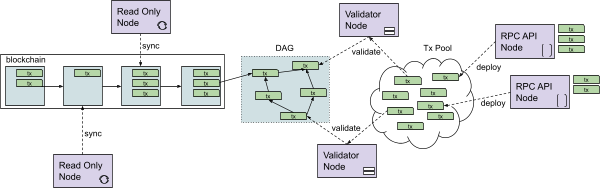
These node types have in common that they run software called the Opera client.
The Opera software has a lot of work to do: It must have a database storing Fantom’s ledger that grows over time and stores account details, including balances and smart contracts. Opera must also run a virtual machine to execute smart contracts on the blockchain directly. Lastly, Opera has a complex network protocol to keep the peer-to-peer network up and running and uses consensus algorithms, ensuring that the ledger is secure and consistent.
As you can imagine, the Opera client is busy doing all this work involving vast data amounts accrued over time. To date, Fantom’s blockchain has 42 million blocks (in July 2022) whose transactions must be stored safely in a cryptographic database.
You may wonder why the design and implementation of the Opera client may impact you as a Fantom user. The answer lies in the processing speed of Fantom’s network: how many transactions per second Fantom’s network can sustain and how fast a single transaction can settle on the ledger. Fantom’s network is fast (a block is confirmed between 1 and 2 seconds, see FTMscan), but the question is whether Fantom’s network can be made faster.
Clearly, faster internet connections and servers would achieve higher transaction throughput and lower latencies. However, a more economical approach is to improve Opera by finding better algorithms and data structures and fine-tuning the software.
TL;DR (jump to What’s next)
Profiling
As a first step, we need to measure the runtime of its components to understand Opera’s performance bottlenecks.
This process of measuring the runtime of Opera’s components is called Profiling [Computer Systems: A Programmer’s Perspective, 2015 https://csapp.cs.cmu.edu], which injects instrumentations into the source code. The instrumentations measure runtime and frequencies of software components while running Opera.
For profiling, we have instrumented the source code of Opera. The instrumentation added hooks for taking timestamps at the beginning and end of software components. The instrumentation can be found on Github [https://github.com/hkalina/go-opera/tree/txtracing-1.1.1-rc.1-metrics]. We collate and visualize the measurements with the data analytics program Grafana to identify the performance bottlenecks in Opera.
In our profiling setup, we used an Opera client that was disconnected from the network and read network events from a file using the event-imports feature. The imported events contained all events from the genesis block to 42 million blocks from Fantom’s mainnet.
Note that the event file was prepared in a previous step (syncing a new read-only node from scratch by enabling the export-events feature in the command line interface). The rationale of our experiment is to achieve a stable measurement without the fluctuations of internet connections and to stress test the system. In a real-world situation, the arrival of events via the internet connection will be orders of magnitude slower than from a file.
The block processing of Opera is shown in the following picture:
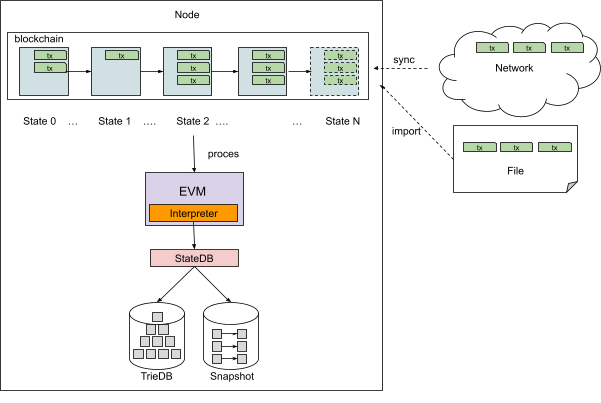
Every node contains its copy of the ledger updated from the incoming network events (either by file or via the internet connection). The ledger’s state is updated as the node executes the transactions in every block. The ledger is changed by modifying Accounts or Smart Contracts Storage (StateDB). The account holds a fixed record of balance, nonce, and the smart contract code with the link to its storage. The smart contracts are executed on the EVM virtual machine. They may modify the Accounts and the Storage. Note that the ledger can keep several database versions throughout the state evolution while executing transactions using a Merkel Patricia Trie data structure.
Our implementation stores the Accounts and Storage in two different formats. The Merkle Patricia Trie uses a tree structure. The Trie must be reconstructed in-memory to map all key-value pairs. In contrast, the second format is the Snapshot format, a flat key-value structure holding a copy of leaf values directly accessible via the key. The Snapshot would not permit several database versions and cannot produce a root signature. However, its access is faster than tedious Merkel Patricia Trie path walks. In our experiments, we have enabled both storage formats.
We have analyzed the following execution points:
- EVM - the time the EVM needs to process a smart contract. It excludes access time to the storage
- StateDB - the time the EVM spends in accessing the storage system
- Code Around Commits - all parts of the code relevant to inserting finished blocks in the database
- Before txs execution - all parts of the code preparing blocks before transactions are processed
- Hashes - time to compute hashes of accounts and storage in Merkle Patricia Tries
The database access time (StateDB) has been furthermore drilled down:
- Storage Updates - every time a smart contract stores a value, i.e. the EVM interprets the instruction SSTORE, the value is not immediately propagated into the Merkle Patricia Trie or the database, but it is stored in a memory map of dirty values for the later flush. The Storage Updates measure the time of propagating these dirty values into the in-memory Merkle Patricia Tries, that is, before becoming persistent data in the database.
- Storage Snapshot Reads - the time a smart contract reads a value, i.e. the EVM interprets the instruction SLOAD, and the value is obtained from the Snapshot.
- Storage Reads - the time a smart contract reads a value, i.e. the EVM interprets SLOAD, and the value is not available in the Snapshot; it is obtained from the Merkle Patricia Trie. This may practically happen only when the Snapshot is disabled.
- Storage Commits - the time measured at the end of the block, where the Storage Trie is finalised, most notably all hashes from dirty nodes are recomputed up to the root.
- Storage Snapshot Commits - the time measured at the end of the block, where dirty values are propagated into the Snapshots
- Account Updates, Snapshot Reads, Commits, Reads - operations on the Storage trie modifying (dirty) accounts. Similarly, as for the storage, a set of dirty account addresses is held through the block processing, and the updates are propagated at the end of the block.
Experimentation
We have conducted the profiling experiment on a server with AMD Ryzen 9 5950X 16-Core (32 virtual cores) Processor with 126GB RAM and a 7TB NVMe drive. We measure the block processing time in the first experiment. In the second experiment, we measure the sub-components of StateDB.
We give the runtime of each component as a percentage of the total runtime for processing all 42M blocks from the genesis block of the mainnet. The result is shown in the following pie chart:
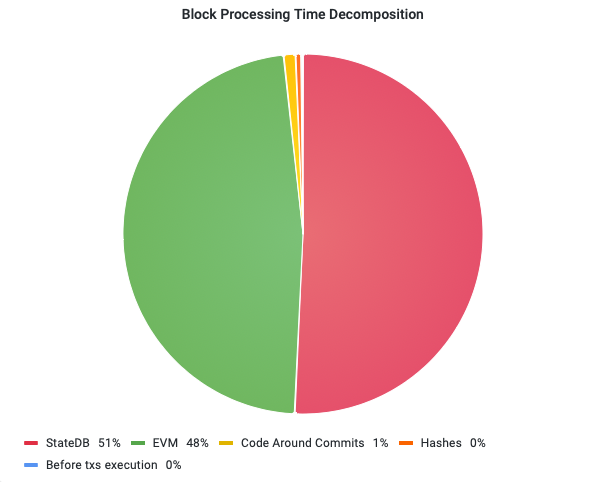
As shown in the chart, the runtime of block processing is dominated by the StateDB (51% of the total runtime) and the EVM virtual machine (47% of the total runtime).
The runtime of other tasks is negligible and would not demand any immediate optimization. Note that the pie chart aggregates the runtimes over time for all 42M blocks and may suppress some workload spikes that may hurt the latency of Opera.
For this purpose, we present the timeline graph for block processing as well:
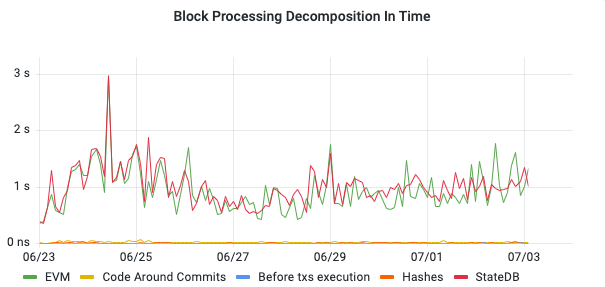
In the timeline graph, we can see that the runtime of the EVM virtual machine and StateDB fluctuates due to the varying complexities of smart contracts.
We see that the workload of the EVM virtual machine and StateDB are highly correlated, and other components of block processing do not exhibit workload spikes. The timeline graph gives us high confidence that the StateDB and EVM components are the main targets for performance engineering; other components do not require immediate optimizations. Furthermore, we cannot see any slow-down trends in the timeline graph.
In the second experiment, we analyze the StateDB by breaking up its runtime into its sub-components:
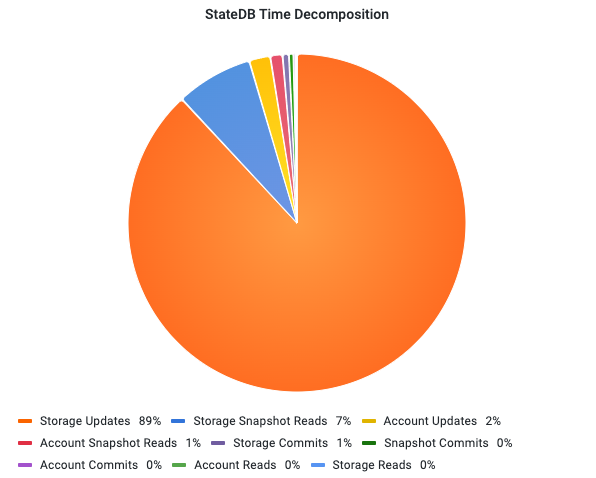
The pie chart shows that most of the time (89%) is spent on the Storage Updates operation.
This operation is invoked after the execution of smart contracts. The smart contracts may have modified their storage in the snapshot, and the modifications must be reflected in the Merkle Patricia Trie. This operation is expensive because affected portions of the Merkle Patricia Trie must be loaded into memory for calculating new hash values. Surprisingly, the actual calculation of hashes is efficient due to modern CPUs and highly fine-tuned hash libraries compared to loading the existing trie nodes into memory.
Note that writing the trie to the key-value database is not included in the runtime of the Storage Update operation as it happens later via fast bulk inserts.
The other relevant operation in StateDB (but still modest in comparison with the UpdateTrie operation) is the Storage Snapshot Reads operation, with a total of 7% consumption. This operation is fast due to the direct access to the values via the flat key-value structure. However, it leaves the complete preparation of the Tries for the later Storage Update operation.
The operation Account Updates is similar to Storage Updates, but applied to the modification of accounts. Interestingly, it consumes only 2% despite using the same ways of storing the data. Other account operations are even lower.
We have also analyzed the timeline graph for the subcomponents of the StateDB:
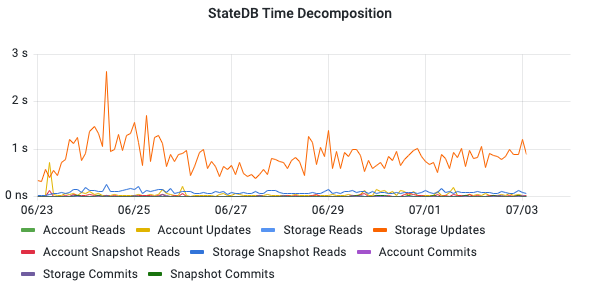
The timeline graph shows that Storage Updates is the runtime dominant operation in StateDB.
We cannot observe trends of slow-down over time. The performance remains fluctuates with the complexity of the transactions. On average, accessing the storage and interpreting a smart contract oscillates between 0.5s and 2s.
In summary, the profiling of the mainnet for the first 42M blocks shows that the block processing spends 51% of its time in StateDB and 48% of its time in the EVM virtual machine; other activities in block processing are negligible. The Storage Update operation in StateDB is performance dominant.
What’s next
We have seen that profiling Opera highlights potential performance bottlenecks of block processing. The profiling experiment was an extreme stress test, i.e., network events were read from a file rather than imported via a much slower internet connection.
Our experiment revealed that the StateDB and the EVM use up to 99% of the block processing time in roughly equal portions.
Based on the profiling experiment, we see two major directions to understand and improve the performance of Fantom’s Opera client:
- a more detailed performance investigation of the Storage Update operation in StateDB and improvements for it, and
- an in-depth study of the EVM and its performance improvements.
Authors
Kamil Jezek
Kamil finished his Ph.D. at the University of West Bohemia, Pilsen in the field of computer science. His research included Software components, static program analysis, compatibility, reverse engineering, byte-code, and non-functional properties. He later moved his focus to blockchains and worked with prof. Bernhard Scholz as a postdoc at the University of Sydney. The topics included performance, storage systems, and virtual machines. Kamil has also extensive experience as a software engineer and architect, where he implemented enterprise and cloud applications.
Bernhard Scholz
Bernhard Scholz is a Full Professor in the School of Computer Science at The University of Sydney. He specializes in Programming Languages, and has published several papers on smart contract security in 2016. Prior to Fantom he was the founder of Souffle, a Datalog language that is mainly used for static program analysis by companies such as Oracle. He is also the co-founder of Sun Microsystems Lab in Brisbane, where he co-initiated the bug-checking tool Parfait, a de facto tool used by thousands of Oracle developers for bug and vulnerability detection in real-world, commercially sized C/C++/Java applications, as well as the Partitioned Boolean Quadratic Program for compiler design used in LLVM.
Jirka Malek
Jirka graduated from the Academy of Defense, Brno with focus on data analysis, processing, and security. He has more than 20 years of experience as a system analyst, a database architect, and a developer of IT projects, including Lead Analyst and CTO of a manufacturing-oriented ERP system. He is now a developer of Fantom's APIs and backend services, and an advocate of energy efficient and sustainable blockchain technologies.
Jan Kalina
Jan graduated from Brno University of Technology. He worked on performance analysis for Oracle Netsuite before he joined Fantom.