Faster with Off-The-Chain Testing

Performance Engineering is crucial to making blockchain software more efficient. One of the primary reasons for performance engineering is to run software with fewer resources.
For example, when performance engineering is applied effectively, blockchain software will run faster and consume less energy, which is vital for climate change and saving money on energy bills.
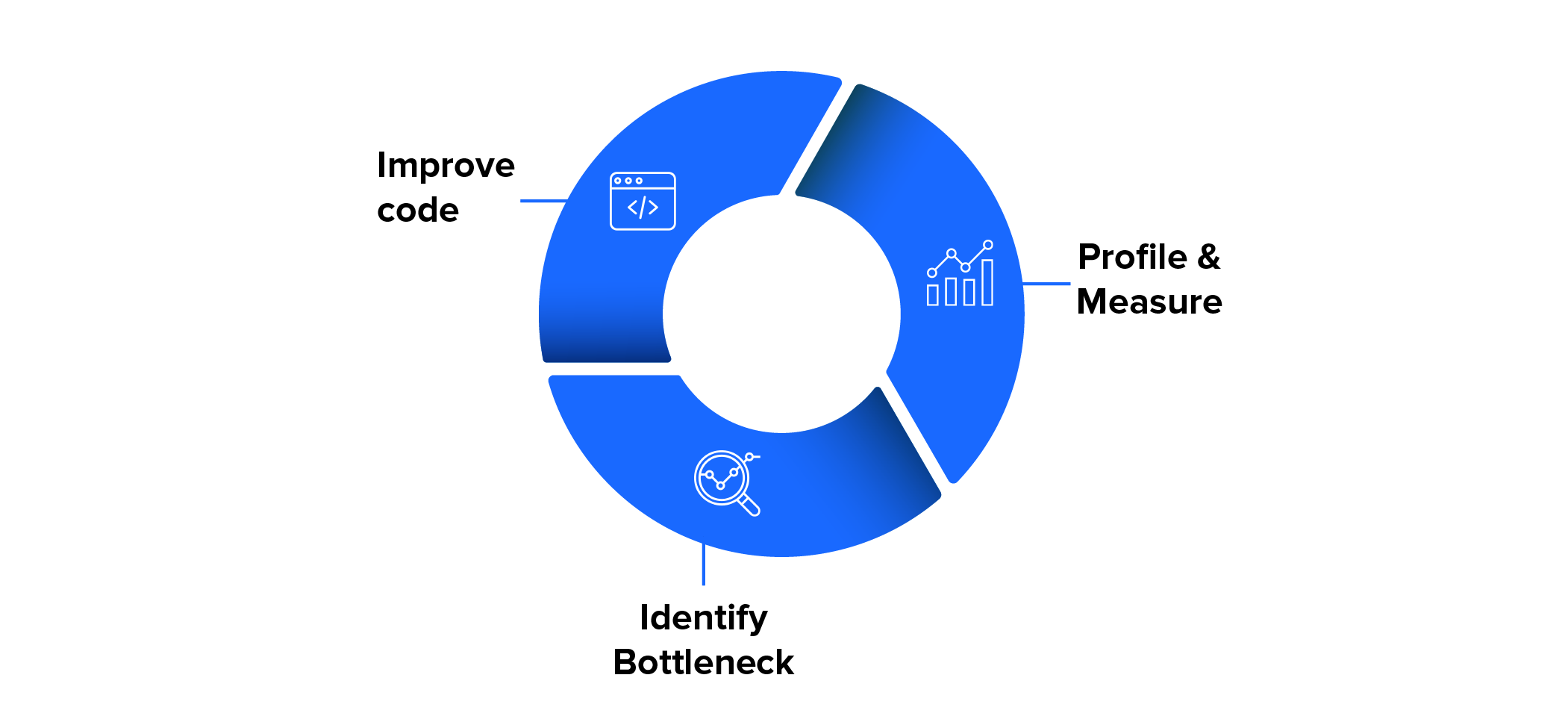
The performance engineering process is continuous and has three major stages:
- The software is profiled by measuring runtime, latency, throughput, etc.
- The profiling data is analyzed, and performance bottlenecks are identified.
- The bottlenecks are eliminated by rewriting the source code.
The rewriting of the software may encompass the replacement of data structures/algorithms and the fine-tuning of program parameters. After the third stage, the performance engineering process continues by repeating the first stage.
Unfortunately, end-to-end performance experiments for blockchains require patience. For example, a performance experiment for Fantom’s blockchain will take two to three weeks to complete a full import of Fantom’s mainnet.
If you possess only a single machine for performance testing, you can have at most ten to twenty performance engineering cycles in a year in the best case. In an agile programming environment, this is not good enough.
The primary problem lies within the blockchain’s sequential nature of block processing, which determines the duration of the first stage in the cycle. The virtual machine processes transactions one after another to keep a consistent state for smart contracts. Overcoming this sequential nature of block processing is challenging.
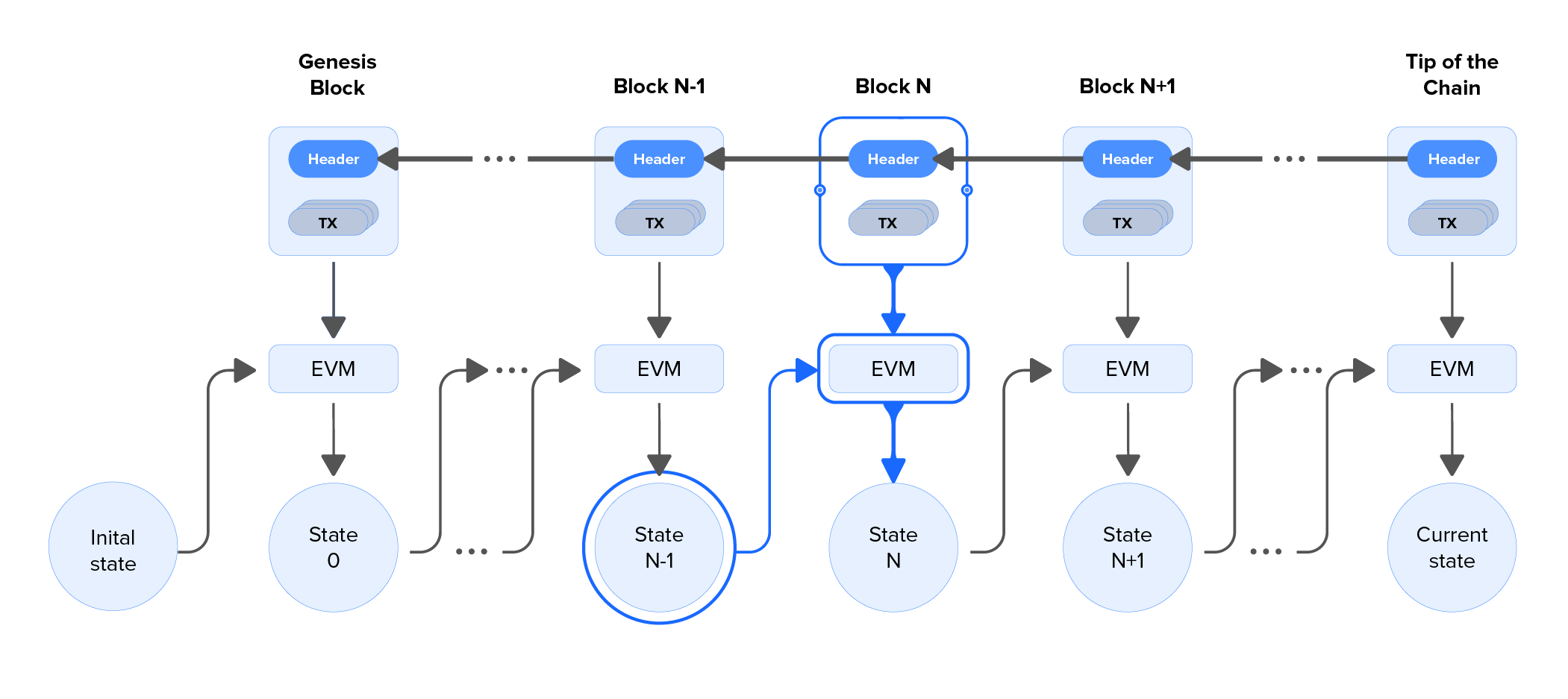
As shown in the above figure, the block processing includes the Ethereum Virtual Machine (EVM) and starts with the genesis block and an initial state. Then, the virtual machine evolves a new state from the next transaction and the old state. The final state of a block is handed over to the next block. The transactions in the N-th block require the state N-1 from the previous block.
Academics from Yonsei University and the University of Sydney solved this sequential testing dilemma. They presented a new end-to-end testing framework for blockchains at USENIX ATC '21 with the title An Off-The-Chain Execution Environment for Scalable Testing and Profiling of Smart Contracts. It is an off-the-chain testing framework that can run each transaction in isolation.
We have adapted the Off-The-Chain testing framework for Fantom recently.
As a result, the block-processing of Fantom’s blockchain takes just 2 hours and 40 minutes on average on an AMD Ryzen 9 computer instead of approximately 2-3 weeks for profiling.
Off-The-Chain Testing Framework
The Off-The-Chain testing software has two components.
The Recorder
The first component is called the Recorder. The task of the Recorder is to transcribe the blockchain into a Substate Database. The Substate Database contains the most minimal information for executing an arbitrary transaction in the blockchain.
For example, if a smart contract is invoked in the transaction, only the storage addresses that are accessed in the smart contract execution, are captured in the substate database; other addresses are omitted. Likewise, a transaction may have several smart contracts involved - only their substates are stored in the Substate Database for this transaction; the states of other substates are ignored.
Constructing the Substate Database takes time since the Recorder must process all blocks of the blockchain to create the Substate Database.
The Replayer
However, as soon as the Substate Database is created, we can use the second component of the Off-The-Chain testing software called the Replayer. The Replayer can execute any transaction in complete isolation by loading the substate of the transaction and executing the transaction.
Moreover, the Replayer can execute transactions in parallel and multiple times with different objectives. Hence, the execution of transactions becomes an embarrassingly parallel problem, accelerating the profiling/measuring stage of the performance engineering cycle.
Key to the Off-The-Chain testing framework is the Substate Database, which contains a minimal subset of the World-State Trie to faithfully replay transactions in isolation. The subset contains all the entries represented as a flat key-value store (and is not stored as a slow Merkle Patricia Trie) for executing a transaction.
In addition, the substate is enhanced with meta information that is required for the execution of the transaction, including:
- the values of the input arguments of the transaction,
- the cryptographic hashes needed for the execution, and
- the expected return values.
In the following, we summarize the information stored in the substate:
- Alloc: information about each accessed account, i.e., account address, nonce, balance, code hash, and storage values from the world state accessed by the transaction.
- Block: captures the block environment, including block number, block creation timestamp, block hashes, coinbase, difficulty, and block gas limit.
- Message: nonce, gas price, provided gas, sender account address, recipient account address, input value, and input data to initiate the message call.
- Result: status code, transaction gas usage, logs and their Bloom filter from the output of the transaction execution.
The substate representing the historical world state before executing a transaction is called the input substate. It consists of three parts: input alloc, block, and message. The substate representing the historical world state after executing a transaction is called the output substate. It consists of two parts: output alloc and the transaction result.
Together, the input and output substates contain all information required to faithfully replay and validate any blockchain transactions.
Recorder
The Recorder is an augmented Opera client that collects a smart contract’s set of storage addresses in the world state while executing a transaction. After processing the transaction, the recorder collects the corresponding value from the world state for each accessed storage address to form the substates.
The records in the substate database are indexed by the block number and the transaction number within the block. Each record contains all the necessary information to execute a transaction in isolation and can be accessed by a single database lookup.
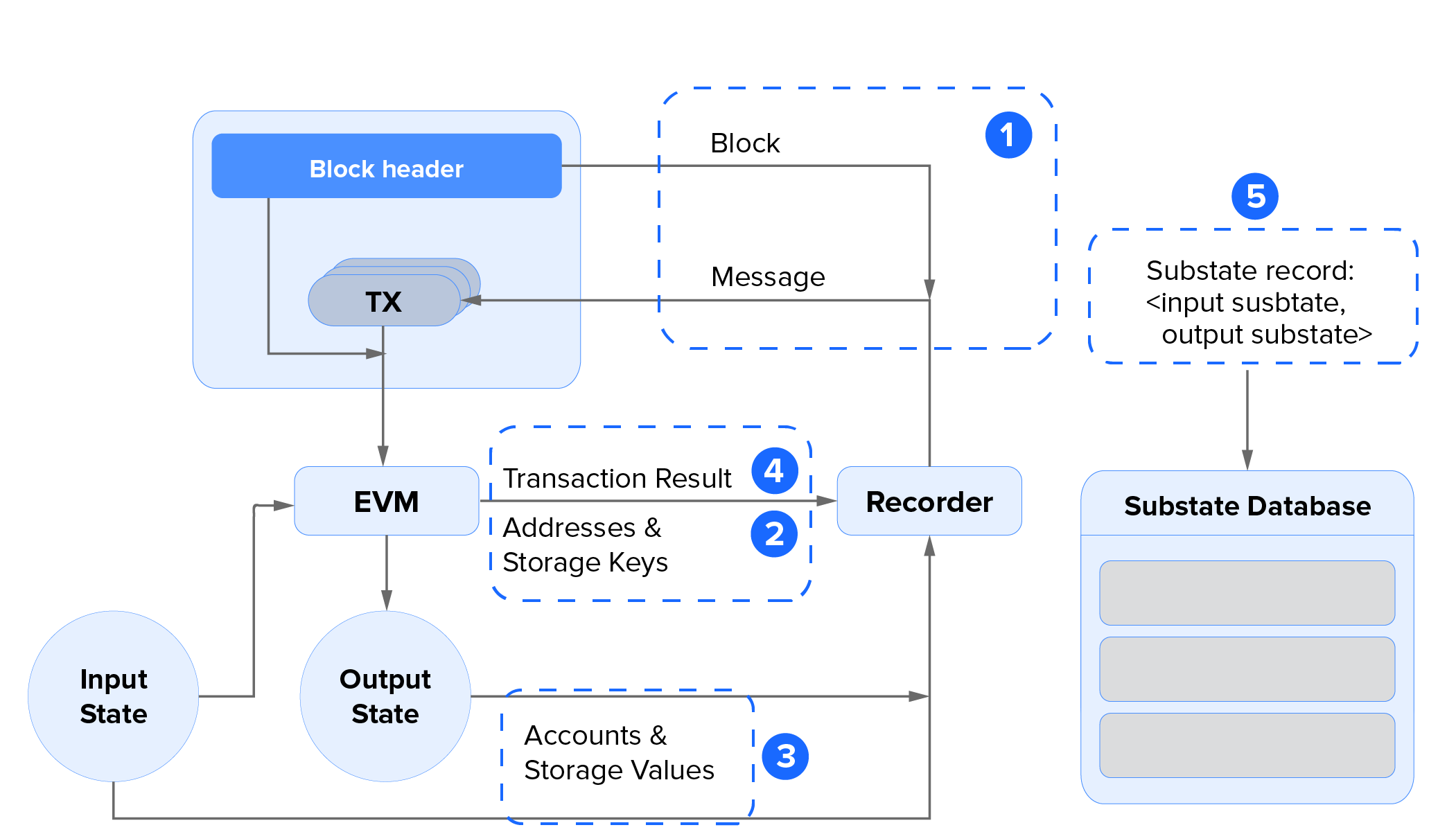
The figure shows the anatomy of the recorder. While performing the block processing inside the opera client, the block environment, the transaction result, addresses, and storage keys are recorded, producing the input and output substates for a single transaction.
The Recorder for Fantom is available at https://github.com/fantom-foundation/go-opera-substate. The recorder records transaction substates via "opera import events" command with the recording option enabled.
$> opera import events --recording fantom_exported_events
The substates are stored in substate.fantom directory by default. The substate directory can be optionally changed by using --substatedir option.
$> opera import events --recording --substatedir /path/to/substate_directory fantom_exported_events
Replayer
The Replay requires only the Substate Database and the Ethereum Virtual Machine to execute a transaction; all other components of an Opera’s client software are not necessary for the replayer.
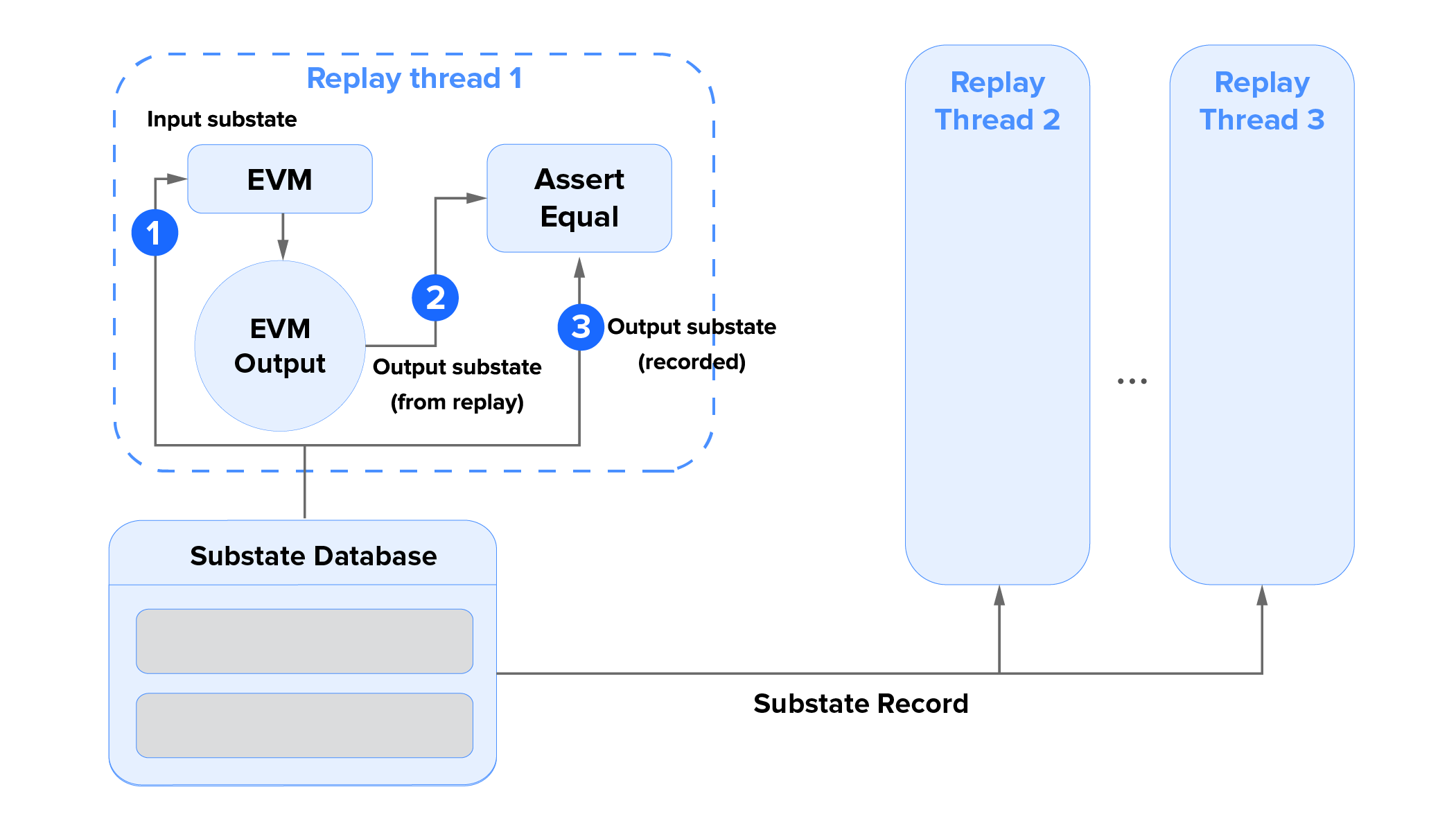
The replayer creates a thread pool for the parallel execution of transactions. For each transaction, a replay thread invokes a new EVM instance with an in-memory context that simulates on-chain features such as hard forks, gas costs, block environment, precompiled contracts, and database snapshots for reverted transactions. After executing a transaction, the replay thread collects the output and validates the output against the recorded output substate. If a thread unsuccessfully replays a transaction, the replayer terminates and reports an error.
Building source code from substate-cli repository generates the substate-cli binary, our Replayer.
$> substate-cli replay 0 41000000
The above command executes substate from Block 0 to Block 41 million. If the execution result in the Replayer does not match to the Recorder result, it is immediately terminated with an error message. The command reads the substate database from ./substate.fantom directory by default. If located in another location, the directory path can be explicitly specified via option --substatedir.
$> substate-cli replay --substatedir /path/to/substate_directory 0 41000000
Substates of the first 41million blocks on Fantom can be downloaded from here. The first 4,564,035 blocks were excluded as they could not be block-processed during import.
Porting Experience
Initially, the record and replay framework was developed for Ethereum (https://github.com/verovm/record-replay). In recent weeks, we have ported the record and replay for Fantom.
The software can be found at https://github.com/fantom-foundation/substate-cli, and https://github.com/fantom-foundation/go-opera-substate.
While porting, we had various issues since Fantom is not Ethereum: Opera’s state transition and state processor implements a different logic adapted for proof-of-stake and the consensus protocol Lachesis. The Replayer uses the EVM transition logic to calculate gas usage and the results of a transition. Its behavior is influenced by the chain environment, including block difficulty, chain id, and hard fork block numbers. However, Fantom uses different parameters than Ethereum (e.g., there are no miners in Fantom; only validators) and the Replayer had to be adapted accordingly.
What’s next?
There are essential metrics to compute for a new virtual machine and a new storage system, including storage and code size, the number of instructions/op-codes executed, frequencies of specific op-codes, etc.
With the Replayer mechanism, the block processing is reduced from 2-3 weeks to 2 hours 40 minutes for the first 41 million blocks of the mainnet. We will keep you up to date with these new metrics in future, explaining the design of Fantom’s new virtual machine.
About the Authors
Wasuwee Sodsong is a member of Fantom’s Research Lab. She received her Ph.D. at Yonsei University and The University of Sydney in 2018 (Cotutelle) under the supervision of Prof. Bernd Burgstaller and Prof. Bernhard Scholz. Her study focused on parallelization techniques for heterogeneous systems, especially on leveraging the key strengths of CPUs and GPUs through code partitioning and dynamic scheduling. Before joining Fantom Foundation in 2022, she worked at SAP Labs Korea as a senior developer on SAP HANA database development, a high-performance in-memory relational database.
Kamil Jezek is a member of Fantom’s Research Lab. He received his Ph.D. from the University of West Bohemia, Pilsen in computer science. His research includes Software components, static program analysis, compatibility, reverse engineering, byte-code, and non-functional properties. He later moved his focus to blockchains and worked with Prof Bernhard Scholz as a postdoc at the University of Sydney. The topics included performance, storage systems, and virtual machines. Kamil has also extensive experience as a software engineer and architect, where he implemented enterprise and cloud applications.
Herbert Jordan is a member of Fantom’s Research Lab. He received his PhD in computer science from the University of Innsbruck where he studied high-level parallel intermediate representations for heterogeneous high-performance applications, static code analysis, and optimizations. His research laid the foundation for the AllScale project (a European Horizon 2020 project) led and supervised by him as its scientific coordinator. He contributed to the Souffle Datalog engine providing the computational core of many static program and protocol analyses. After a few years as a Google Engineer working on latency improvements across the Google software stack, Herbert joined Fantom Research to focus on VM, storage, and service performance challenges
Bernhard Scholz is a Full Professor in the School of Computer Science at The University of Sydney. He specializes in Programming Languages, and has published several papers on smart contract security in 2016. Prior to Fantom, he was the founder of Souffle, a Datalog language that is mainly used for static program analysis by companies such as Oracle. He is also the co-founder of Sun Microsystems Lab in Brisbane, where he co-initiated the bug-checking tool Parfait, a de facto tool used by thousands of Oracle developers for bug and vulnerability detection in real-world, commercially sized C/C++/Java applications, as well as the Partitioned Boolean Quadratic Program for compiler design for LLVM.