Introduction to PebbleDB Pre-release

What is PebbleDB?
PebbleDB is a key-value database developed by Cockroach Labs. Written in Go, it is based on a port of LevelDB with additional features and optimizations inspired by parts of RocksDB. PebbleDB is an alternative to the default LevelDB currently used for the persistent storage of events, transactions, and world state data in Opera client.
Based on our experimentation, the main benefit of PebbleDB is the significant reduction in I/O bandwidth usage (~90%) we have experienced in production.
Do we need PebbleDB?
The default LevelDB backend is proven to be stable and performs very well in most common scenarios, but API nodes with high volume of client calls face a problem of large numbers of parallel random reads being requested from the database. This is a case where LevelDB cannot keep up with demand. We tried several different available solutions to address this problem, and PebbleDB came out as a backend with the fastest parallel reads throughput for RPC nodes..
There are some key differences between LevelDB vs PebbleDB:
- LevelDB is designed to run on slow disk drives. To operate efficiently, it performs frequent sorting of the stored data. These maintenance operations get costly over time, mostly due to the increasing volume of data being managed. Hence, LevelDB nodes can start lagging behind network overhead when the server is for example under a big and consistent RPC load.
- PebbleDB has been designed to operate on modern, fast, persistent storage drives, namely SSD and NVMe drives, with very low random access time. PebbleDB does not automatically flush its write buffer so often as LevelDB and postpones the data sorting. This leads to lower overall i/o performed by the node.
The key benefit of the PebbleDB is a dramatic reduction of average I/O usage on API server nodes, and a significant reduction of the time to respond for nodes with multiple parallel incoming API requests. Please refer to the Performance results section for more details.
Integrating PebbleDB into go-opera
We have integrated PebbleDB into our Go-Opera implementation.
Our performance studies and testing suggest that PebbleDB database-driven nodes handle i/o with far greater efficiency than LevelDB. The i/o throughput is gained with a cost trade-off of lower resistance to DB corruption, especially if the node is facing frequent terminations, or is run on a less error-prone HW environment.
Branches
- LevelDB - branch: https://github.com/Fantom-foundation/go-opera/tree/release/1.1.1-rc.2
- PebbleDB integration: initial version is available in this branch https://github.com/Fantom-foundation/go-opera/tree/release/1.1.1-rc.2-pebble
Recommendations
We recommend using PebbleDB only for high throughput RPC nodes. The key benefit is a dramatic reduction in memory usage and disk I/O.
Note: The PebbleDB backend is an experimental feature. We do not recommend running your mainnet validator node configured for PebbleDB.
Please make sure you run the PebbleDB-driven node only in an experimental environment, API node, and/or private test node. We have done thorough testing of PebbleDB, but we still consider it to be an experimental feature. We firmly discourage using the PebbleDB backend for production environments in most cases, especially to run PebbleDB-driven nodes in the validator mode. We do not yet support this feature , and you can lose your stake by implementing it.
Compatibility
PebbleDB is not compatible with the default LevelDB, and a migration tool is not available at this moment. To use this PebbleDB version, it’s recommended to launch a fresh new node or to run with a new datadir.
You will need to either remove the LevelDB database before syncing the node with the PebbleDB backend, or choose a different data dir path for the PebbleDB version.
Data
The default behaviour of the PebbleDB version of the Opera remains the same as with the LevelDB. The datadir contains 3 folders (chaindata, go-opera, and keystore), and running Opera also places the IPC communication socket file there.
The chaindata database structure is generally the same as with the LevelDB, the only major difference is that the LevelDB uses large amounts of small files with .ldb extension, while PebbleDB uses smaller amounts of large files with .sst extension.
Performance results
Our performance comparison experiments setup consist of two bare metal nodes with AMD Ryzen™ 9 5950X, 16 core (Zen3) processor with SMT, 128 GB RAM, and 2x 3.84TB NVMe drive in ZFS RAID 0 for the Opera data storage. The node “pebble130” runs the PebbleDB version of go-opera client, and the node “leveldb211” runs the most recent LevelDB version of the go-opera client (as off 8/2022; both nodes’ versions are 1.1.1-rc.2).
Servers are fed with real life RPC API calls by a fixed number of parallel connections, the number of threads used is identical for both nodes. We don’t generate synthetic requests for the testing purposes. The Fantom public API interface https://rpcapi.fantom.network is used instead as the source for the executed API call. This should cover the usual use cases of the clients operating on the Opera network. Please note that the differences between LevelDB and PebbleDB node performance are much smaller, if not negligible in some cases, if the nodes are not processing external requests on top of the regular network traffic.
Measurement metrics are collected directly from each of the Opera nodes using built-in Prometheus metering interface. The data are presented as charts by Grafana.
Data points for the following visualisations were extracted on a lower number of parallel request threads. We didn’t want to overload the LevelDB node with requests it couldn’t process. The average number of RPC calls run on both servers fluctuates around 20 req/s. Please note that the PebbleDB node carries out more requests on average than the LevelDB server, and the number of calls finished by it is also less scattered over time.
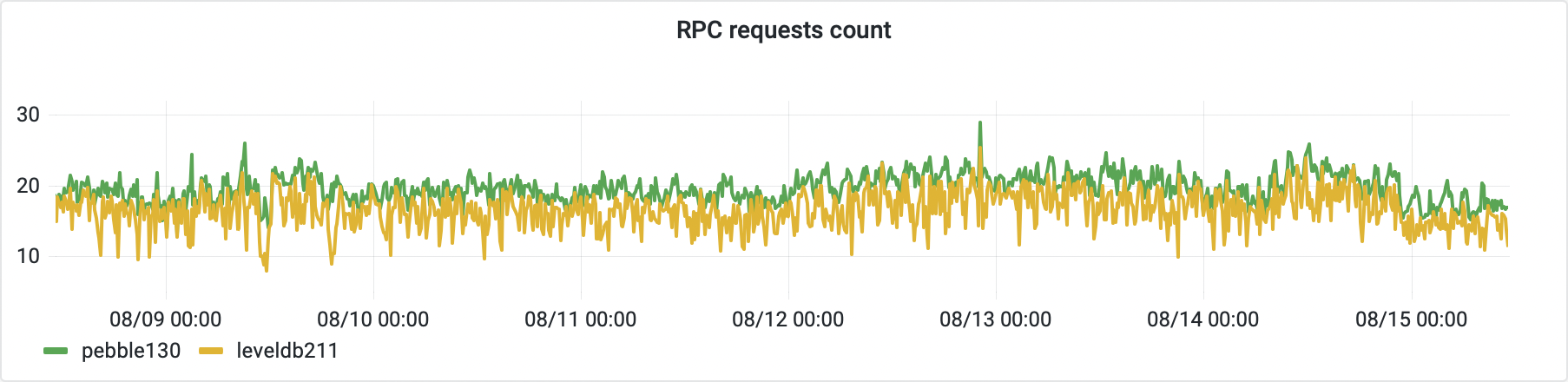
The following chart demonstrates the time needed to confirm a newly formed block. It includes the average time of 99.9% percentile of blocks being added to the chain. The percentile was chosen mainly to remove the internal epoch closing transactions, which are much slower than the regular block traffic.
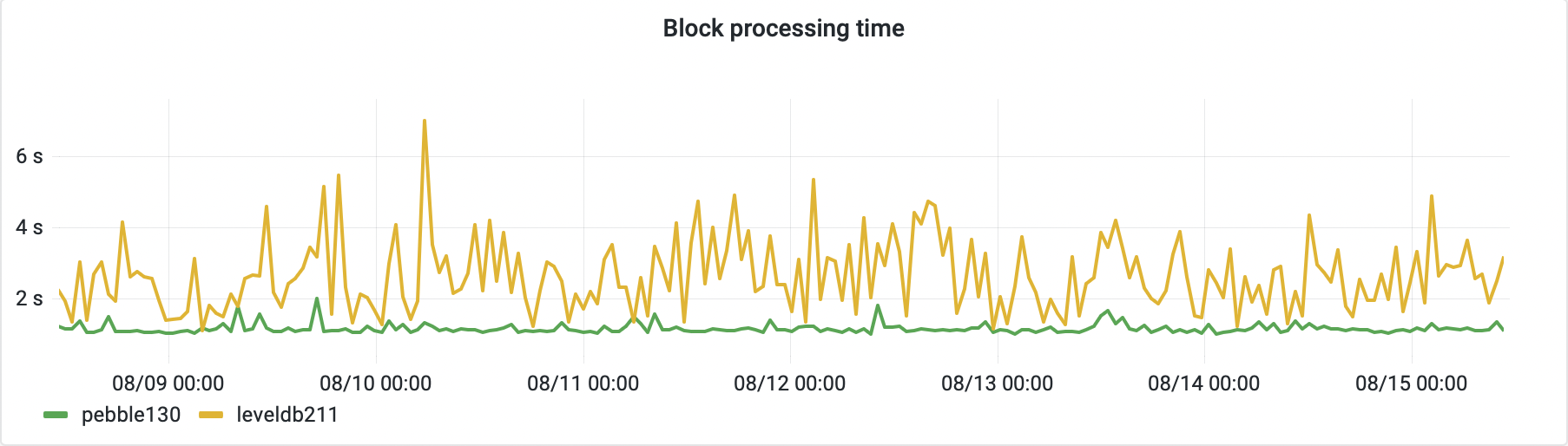
As you can see, the PebbleDB node block insert time is more stable and usually shorter compared to the LevelDB node under the same load.
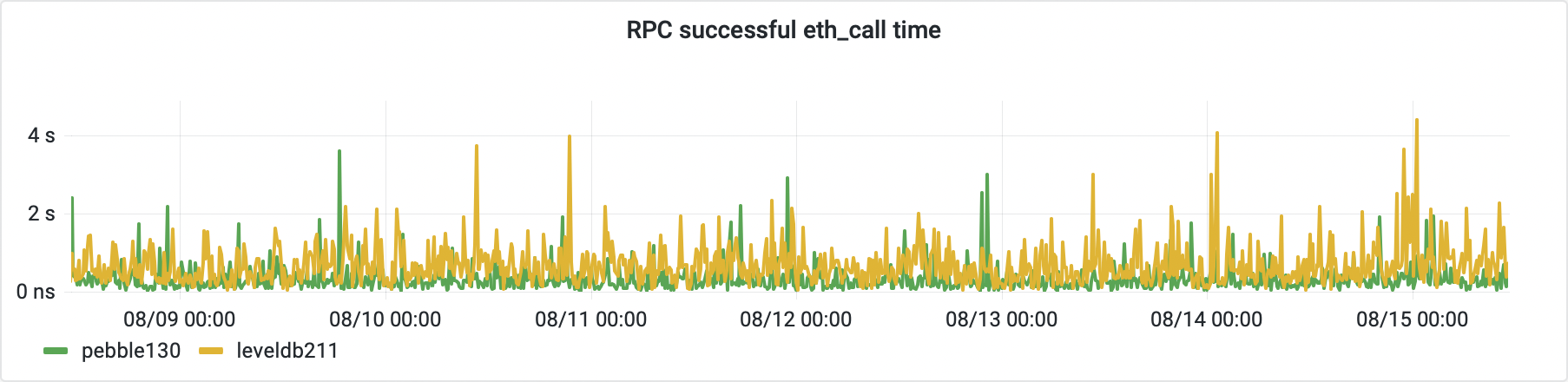
The eth_call requests are executed by about 30% of all the queries processed on the public API interface. This type of request basically allows clients to interact with the smart contracts deployed on the network, and along with the block examination, account balance checks, and emitted events loading represent the majority of resolved client questions.
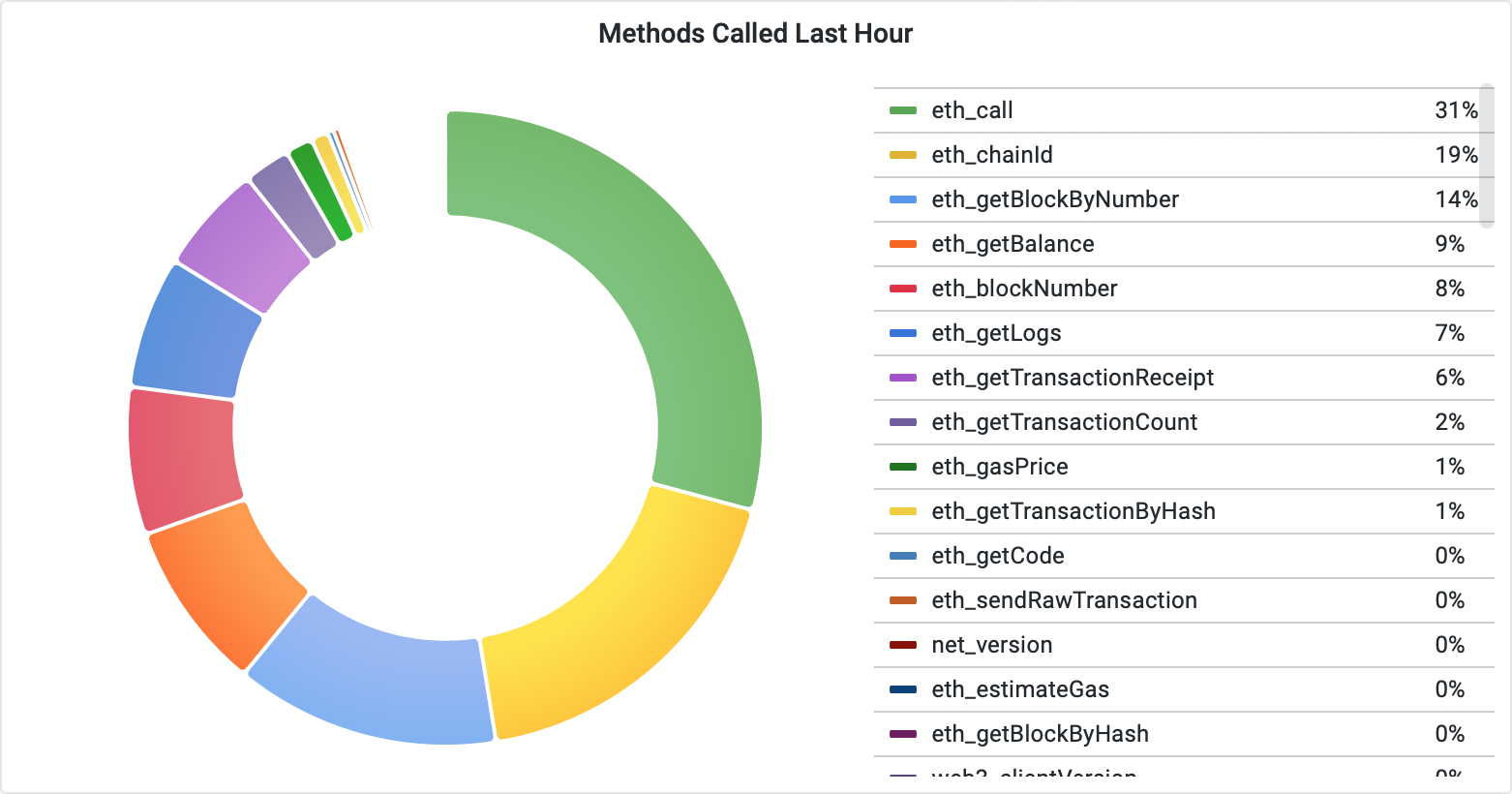
Naturally, we were interested in the time needed to resolve these common lookups. The block loading, and an account balance is resolved mostly in the same amount of time on both servers. The contract interaction, on the other hand, shows that the LevelDB node spends more time collecting the response on average.
The key benefit we get from the PebbleDB node is expressed in the average I/O, used by the database to exchange data with the persistent storage.
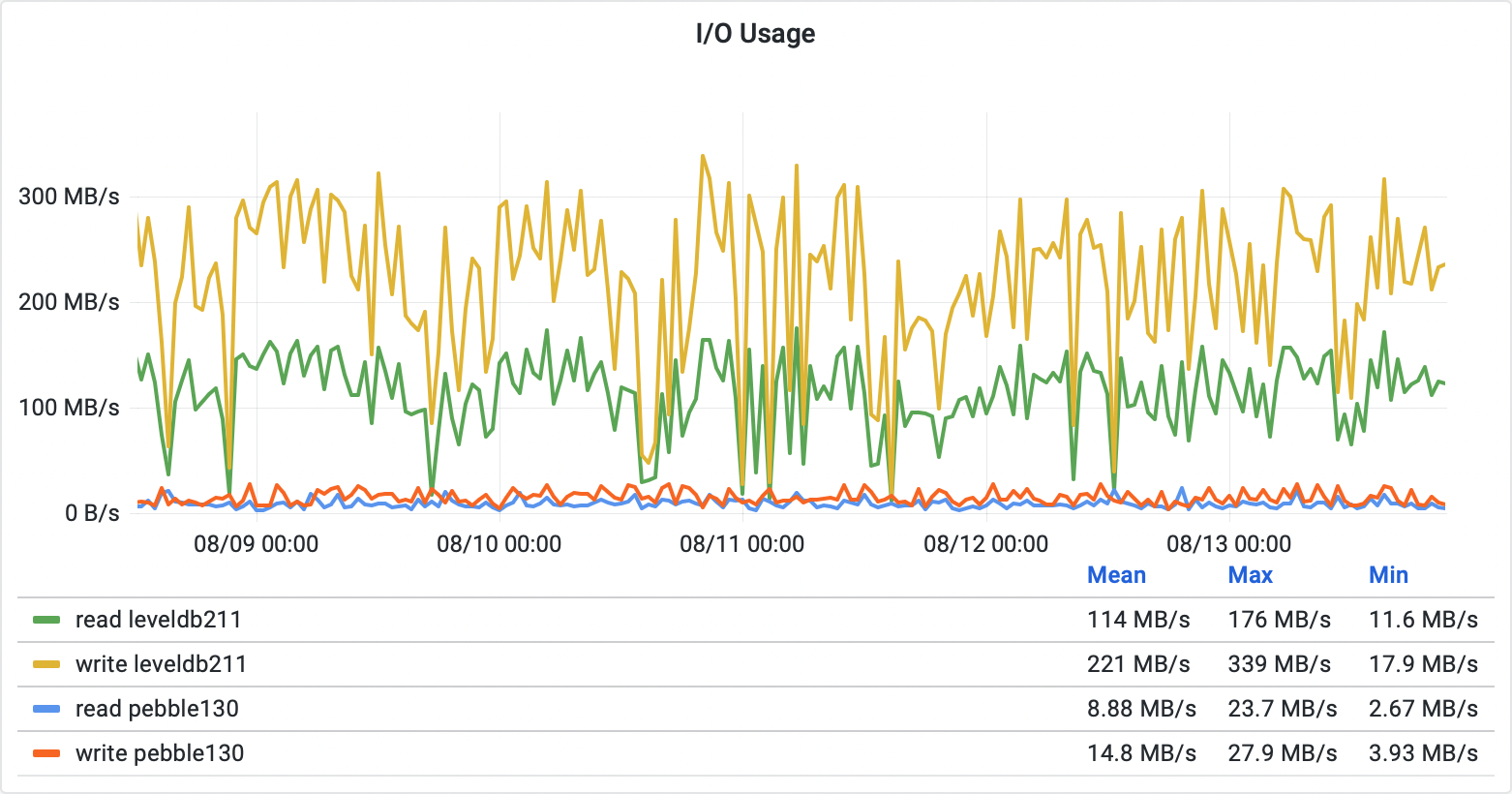
Here, PebbleDB shows its major downside. The database gains its speed mostly from I/O writes optimizations and from postponing the internal maintenance tasks. But of course, it still needs to execute them eventually. Also, the I/O throughput is more likely to be affected by the operating system procedures executed on the drives themselves, i.e. trim. For these reasons, spikes in the demanded I/O throughput may occasionally be much higher on PebbleDB compared to LevelDB.
Recommended hardware / OS
The most important difference between the LevelDB and PebbleDB is the expected behaviour of the underlying storage hardware. For this reason, we strongly recommend NVMe drives, preferably in a RAID0 configuration, for the PebbleDB backend. The other hardware parameters are generally the same as for any other Opera node and depend highly on the intended use.
What next?
The latest pre-release includes that PebbleDB integration plus several optimizations in go-opera:
https://github.com/Fantom-foundation/go-opera/tree/release/1.1.2-rc.1
We’ll introduce it in the next post.